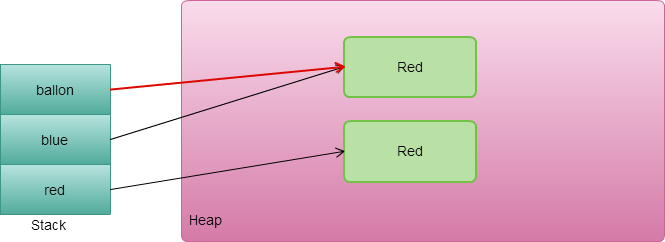
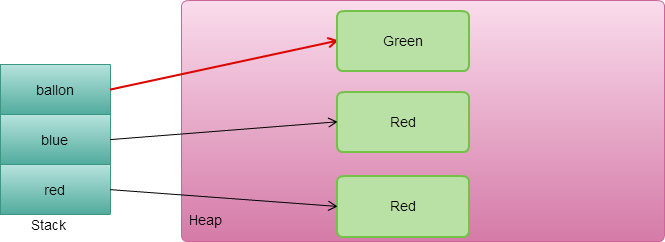
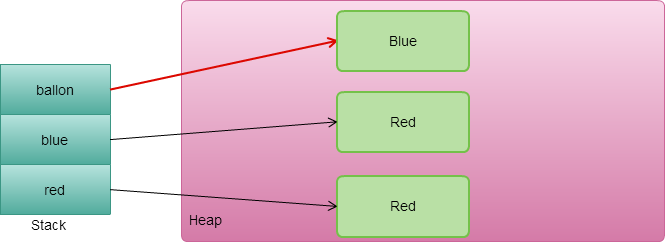
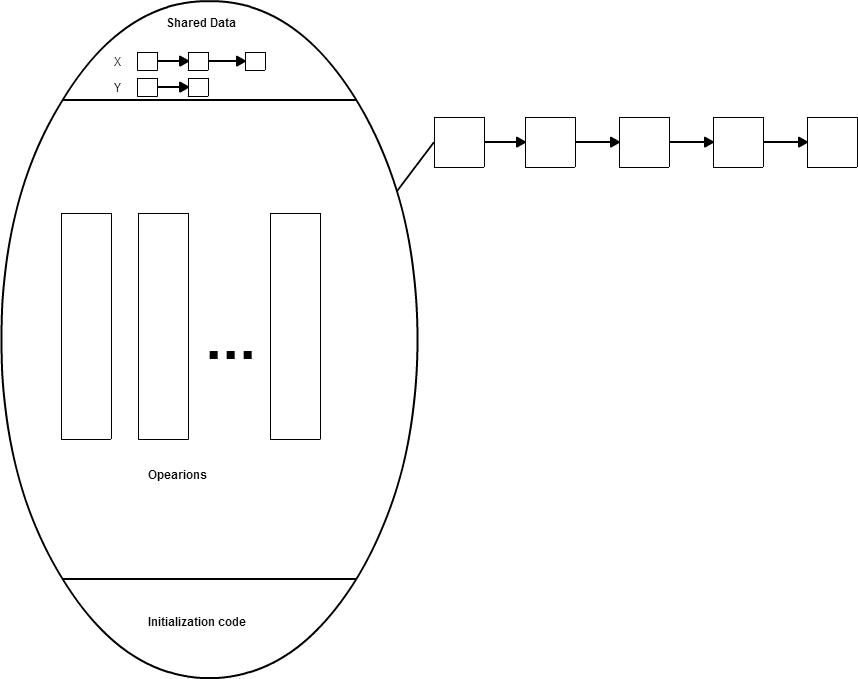
在正常情況下,當執行完 try 的最後一行或是要把控制權轉交給它的呼叫者 (return 或丟出 exception)時,會執行 finally ,當 finally 執行完畢,再把控制權轉交給 try。
但是當在 finally 裡面寫下 return, throw exception, continue, break 會沒有辦法把控制權轉交給 try,造成不可以預期的結果。所以千萬不要在 finally 裡面 return 或丟出 exception,雖然現在的 IDE 都會聰明到幫你檢查出來。
主要原因 try-finally 轉成 Java byte code 時候,finally 是一個副程式,當 try 執行完畢時候就會去呼叫 finally 副程式。當 finally 副程式執行完畢,會跳到 try 的記憶體位置。但在 finally 裡面加了這些return, throw exception, continue, break,它就提前跳出程式回不到正確的位置。
另外,當 try 裡面強制中斷 JVM 或是非預期的情況發生提早結束 (這裡所指的非預期的情況不是丟出 exception,而是當下的 thread 突然死掉或是 JVM 突然有問題這類的。),finally 是不會執行的。
Try-finally clause
1 | try { |
Example 1
1 | int i = 0; |
Example 2
1 | public static void main(String[] args){ |
Example 3
1 | public static void main(String[] args) throws Exception { |
Example 4
1 | public static void main(String[] args) throws Exception { |
Example 5
1 | public static void main(String[] args) throws Exception { |
Example 6
1 | public static void main(String[] args) throws Exception { |